4. Corpus
4.1 Legal translation
As a genre of standard written translation, this study has chosen to focus on legal translation, as opposed to other types of translation such as literature or magazine articles. One reason for that choice is that legal texts often have long, complex sentences, which is where the translation difficulties highlighted in this study are most likely to appear. Another reason is that, in addition to difficulty in the translation process, product-related issues, such as distortions of meaning or coherence and comprehension difficulty for the reader, can have major consequences in legal translation.
Within the category of legal translation, three major international documents are analyzed: the Universal Declaration of Human Rights, the Paris Agreement on climate change and the US Foreign Corrupt Practices Act.
4.2 Subtitle translation
For subtitle translation, this study has chosen to analyze five different TED talks, as opposed to other types of subtitle translation, such as translation of subtitles for films or entertainment series. The reason for this choice is that other types of subtitle translation tend to involve a lot of dialogue consisting of simple sentences, where the translation difficulties highlighted here are unlikely to appear. In contrast, lectures by single speakers who are experts in their fields tend to have more complex sentences. Among online lecture platforms, TED is probably the most widely watched, with hundreds of millions of views.
Because of their large global reach, the choice has been made to analyze the five most popular TED talks, according to the website for the most popular TED talks of all time. The five talks considered in this study are: “Do schools kill creativity?” by Sir Ken Robinson, “Your body language may shape who you are” by Amy Cuddy, “How great leaders inspire action” by Simon Sinek, “The power of vulnerability” by Brené Brown and “Inside the mind of a master procrastinator” by Tim Urban.
4.3 Simultaneous interpretation
As a genre of interpretation, this study has chosen to focus on simultaneous interpretation, as opposed to other forms of spoken interpretation such as consecutive, liaison, community or telephone interpretation. The main reason for this choice is that the working memory constraints which can have a major effect on the linear order and hierarchical structure of complex sentences, particularly in language pairs where subordinate clauses branch in opposite directions, are most prevalent in simultaneous interpretation.
Within the category of simultaneous interpretation, this study has chosen to analyze recordings of interpretation of former US President Barack Obama’s speech to the UN General Assembly on 28 September 2015. One reason for choosing to analyze a speech to the UN is that organization’s unique international scope. Another reason is that three of the languages considered here – English, Russian and Mandarin – are official UN languages, so sessions of the General Assembly are interpreted simultaneously into those languages by expert UN staff interpreters.
Recordings of the original English speech and of the Russian and Mandarin interpretation were obtained with permission from the UN Audiovisual Library. Interpretation into Hungarian, Turkish and Japanese was kindly provided and recorded by expert freelance interpreters for this study. All five interpreters were working with a written copy of the original speech provided shortly beforehand, but without a prepared written translation.
5. Statistical analysis
This study analyzes 1,136 sentences, in the three modes of language transfer mentioned above. For each sentence, the semantic structure of the original English version is compared to that of its translation or interpretation into five languages from different families – Russian, Hungarian, Turkish, Mandarin and Japanese.
The analysis included three independent variables. The first independent variable was mode of language transfer (legal translation, subtitle translation or simultaneous interpretation). The second independent variable was structural difference of the language pair, referring to differences in the branching direction of subordinate clauses. The third independent variable was sentence complexity, referring to the number of functionally subordinate propositions in the original English version of a sentence. (A functionally subordinate proposition is one which doesn’t make an assertion and can’t be rephrased as an independent sentence.)
The analysis also included three dependent variables, recorded separately for each translated or interpreted version of a sentence. Those dependent variables were counts for the three features identified as indicators of difficulty in translation or interpretation – reordering, nesting changes and changes in semantic relations. Counts for nesting changes were subdivided into counts for changes in single nestings and double nestings.
The analysis first produced descriptive statistics reflecting the value of each dependent variable corresponding to each pair of independent variables as observed in the corpus data. On that basis, predictions were made using a generalized linear mixed-effects model for each dependent variable. The models were estimated using the glmmTMB package for the R computing environment. The estimated models were used to predict the mean response of each dependent variable to the three independent variables. If our corpus is considered representative, those predictions can be generalized to other similar texts and speeches.
6. Results
The first step in the predictive analysis was to check for significant interactions between our three independent variables – mode, structural difference and sentence complexity. To do that, the p‑value, or chance of randomness, was computed for the three pairwise interactions between those variables. Each pairwise interaction between mode, structural difference and sentence complexity yielded a p-value of less than 0.05 and can therefore be regarded as significant for all three indicators of difficulty. In other words, each independent variable interacts significantly with the other two. So our statistical tests predicted the combined effect of all three independent variables on each indicator of difficulty.
Let’s start with the combined effect of those independent variables on reordering. The predicted mean rates of reordering per sentence are visualized in Chart 1.
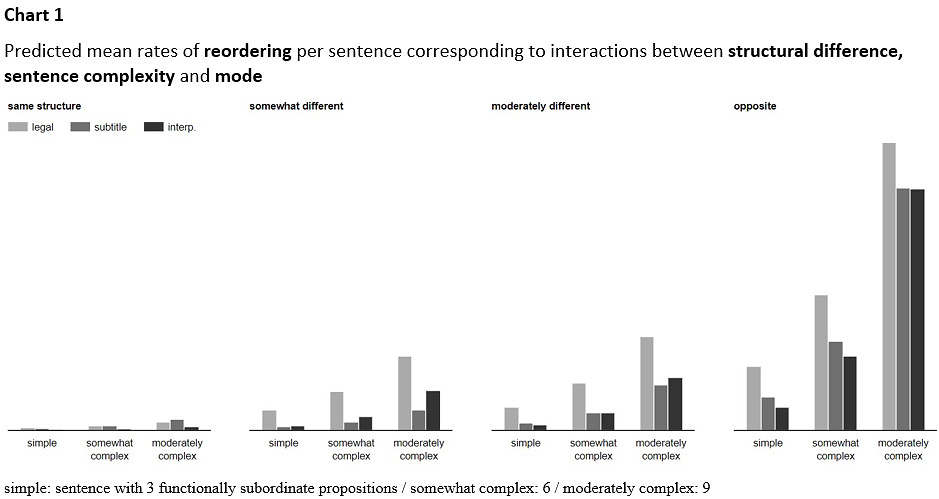
a bit more in legal translation than in the other modes
Let’s look next at the combined effect of the independent variables on changes in single nestings. The predicted mean rates of changes in single nestings per sentence are visualized in Chart 2.
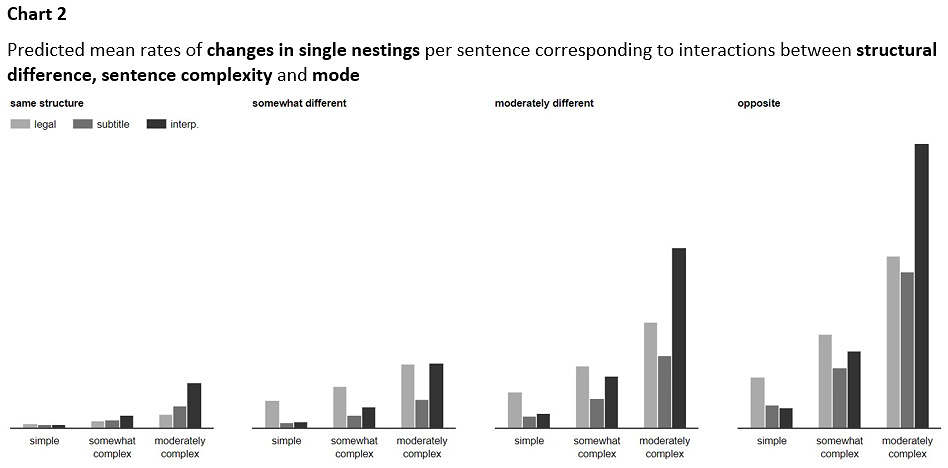
(no clear pattern by mode)
Let’s look next at the combined effect of the independent variables on changes in double nestings. The predicted mean rates of changes in double nestings per sentence are visualized in Chart 3.
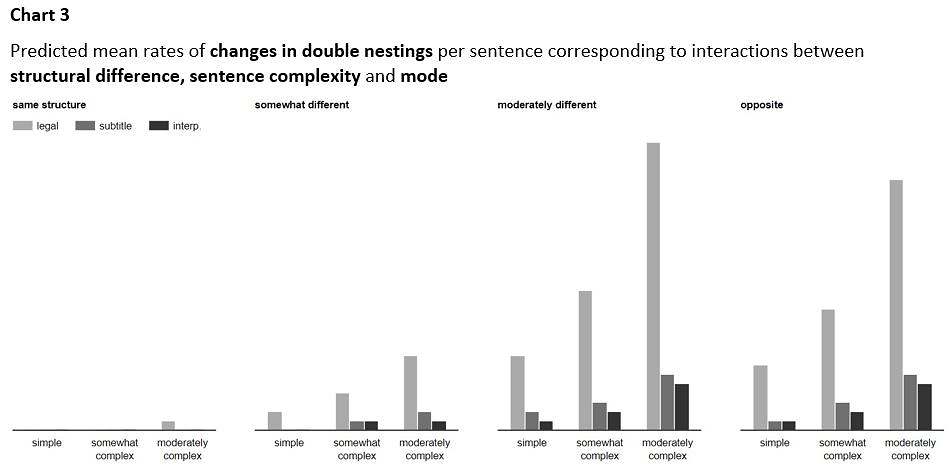
especially in legal translation
Finally, let’s look at the combined effect of the independent variables on changes in semantic relations. The predicted mean rates of changes in semantic relations per sentence are visualized in Chart 4.
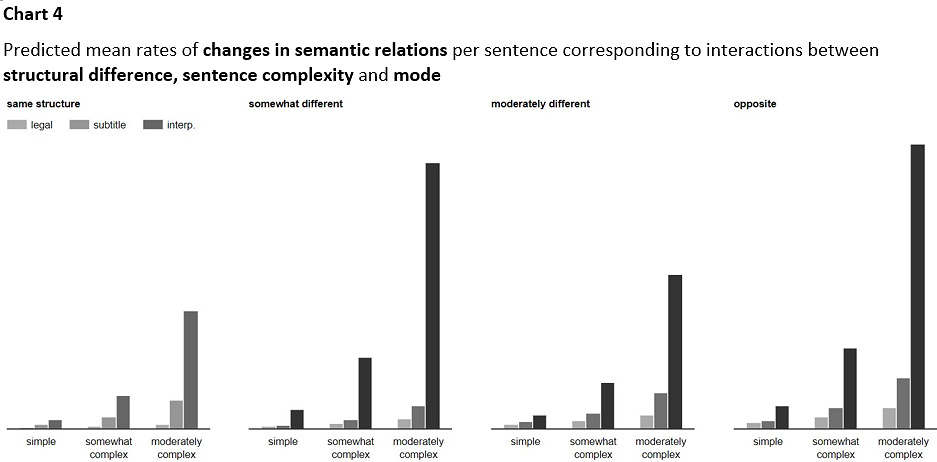
especially in simultaneous interpretation
A reliability check was also carried out on 10% of the sentences in the corpus, to confirm the validity of the data recorded. The new analysis took place several months after and independently from the first analysis. The results confirmed almost perfect agreement between the first and the new analysis.